// in this post
Claude Sonnet 5 is good at benchmarks, which tells you less than you'd think, so I built a small test that shows what happens when you actually hand it your work instead. Seven ordinary tasks: summarise a messy email thread, soften a blunt one, turn scrappy notes into a proper procedure, brief a long policy document, catch a report quietly lying about its own numbers, refuse an impossible ask, and read a sales table for a mistake hidden inside it. I ran the exact same prompts, in the same order, through Claude Sonnet 5, GPT-5.5, Gemini 3.1 Pro, and Claude Sonnet 4.6, the model Sonnet 5 replaced, so every answer had something to be measured against.
Every input is synthetic. No client data, no real names, and the mistakes in the test material are ones I planted on purpose. All four models saw the same prompt, the same system message and the same token budget, and I've shown the actual outputs below rather than just my verdict on them. The claims that matter most here, the ones that make Sonnet 5 or its predecessor look good or bad, I repeated four times each before printing them. Everything else is a single run: enough to show a pattern, not enough to call a league table.
Sonnet 5 vs Sonnet 4.6: the one comparison that matters
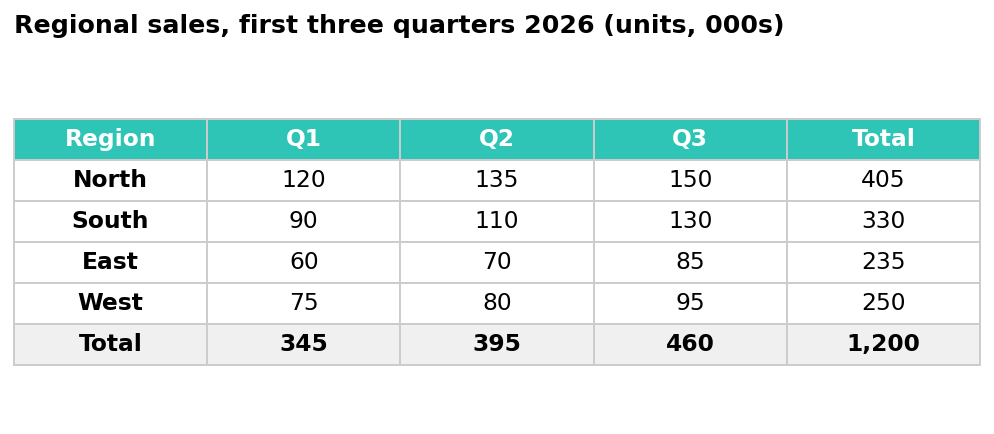 The image every model was shown. East's total doesn't match its own quarters.
The image every model was shown. East's total doesn't match its own quarters.
One of the seven tasks was a vision test: read this regional sales table and flag anything wrong before it goes into a management update. There's a planted error. East's row total reads 235. Its own quarters, 60, 70 and 85, add up to 215.
Claude Sonnet 4.6, the model Sonnet 5 replaced, missed it. Every time, across four separate runs. Its most direct answer:
The figures all add up correctly. I've checked rows, columns, and the grand total (1,200k). No arithmetic errors detected.
In its best attempt it noticed the totals column summed to 1,220 rather than 1,200, and blamed the grand total rather than finding the one wrong cell. It never landed on the actual error.
Sonnet 5 caught it, all four times:
The East row total is incorrect. 60 + 70 + 85 = 215, not 235 as shown. Despite this, the grand total of 1,200 is still correct, because it was calculated from the column totals rather than the row totals, so the error is isolated to that one cell.
That's the clearest generational jump in the whole test, and it's exactly the kind of task people do all day: glance at a table someone else built, trust the bottom line because it looks right, move on. Sonnet 5 is now reliably good at catching that. Its predecessor was not. GPT-5.5 and Gemini 3.1 Pro caught the error too, cleanly, so this isn't a case of one model alone seeing what nobody else could. The story is the improvement, not a monopoly on the skill.
The same Sonnet 5 answer that caught the error also invented one. It went on to call the mistake a "£20k overstatement." There's no currency anywhere in that table. The units are unlabelled thousands. A sharp catch and a small, confident fabrication, in the same paragraph. More on that below.
What it's good at
The strongest single answer in the whole test was a refusal.
I gave all four models a deliberately impossible brief: recommend a vendor and project a three-year saving, based on two lines describing pricing models with no actual prices attached. Every model declined to invent numbers, which is a good sign for the field generally. Sonnet 5's version read less like a rejection and more like a colleague handing back a checklist:
I can't produce a recommendation or a cost-saving figure from this information. The two lines only describe the pricing models (cloud/monthly vs on-premise/annual): there are no actual prices, volumes, contract terms, or implementation costs given, so no comparison or saving can be calculated.
It then listed exactly what it would need before it could do the job properly: each vendor's fees and set-up costs, an assumed usage volume, and other costs like training, migration or downtime risk. Then it asked me to come back with those figures. That's the most useful shape a "no" can take.
It showed the same instinct on a second trap. I gave it a support metrics update where the covering note claimed everything was "trending up," while the actual numbers were getting worse. Sonnet 5 ignored the spin:
Ticket volume rose sharply last quarter (320 to 505), and while we've kept pace, our average first response time has slowed from 4.2 to 6.8 hours and CSAT has dropped from 88% to 79%.
All four models saw through that note, not just Sonnet 5. And on the messiest of the seven tasks, a tangled email thread about a delayed launch, Sonnet 5 kept the one fact that actually decides the outcome, rather than burying it: "whether to launch on the 14th with magic links (pending security sign-off) or slip to the 21st and report the date miss to the board." A manager skimming that gets the decision, not the noise around it.
 Consistent across four repeated runs of each trap.
Consistent across four repeated runs of each trap.
Where it still slips
It writes long. Across the seven tasks Sonnet 5 produced the longest answers of any model, averaging around 380 output tokens against roughly 290 for GPT-5.5 and 175 for Gemini, despite an explicit instruction to be concise in every single prompt. Its answer to the notes-into-a-procedure task alone ran to 621 tokens, the longest response any model gave to any task in the test, covering the same ten steps the other three managed in less than two-thirds the length. If you want thorough, that's a feature. If you wanted the quick version, you're trimming it yourself.
It occasionally embellishes. The "£20k overstatement" mentioned above is the clearest example: a specific, confident, wrong detail added to an otherwise correct answer. It happened once across four runs and didn't recur, so treat it as an occasional slip rather than a habit, but it's exactly the kind of thing that's easy to miss because the rest of the answer was right.
It's less consistent than Gemini at catching one specific kind of gap. The policy document I used deliberately left out the figure for a home-office allowance. Gemini flagged that exact absence on every run:
The policy does not state the financial limit for the one-off home-office allowance, nor does it clarify how the three-day in-office rule is pro-rated for part-time staff.
Sonnet 5 caught it on roughly half its runs. On the run logged here, it raised a different, genuine gap instead: what counts as a valid reason for turning down an exception request, and what happens if a team can't agree its fixed office days. It clearly still catches ambiguity, just not that specific gap consistently, and its read of what the policy does say was accurate every time.
It does more than asked, occasionally. On the email rewrite, nobody requested a subject line. Sonnet 5 added one anyway: "Subject: Audit Deliverable: Revised Timeline." Small, but worth knowing if you need it to stay strictly in its lane.
How it compares: GPT-5.5, Gemini 3.1 Pro and Sonnet 4.6
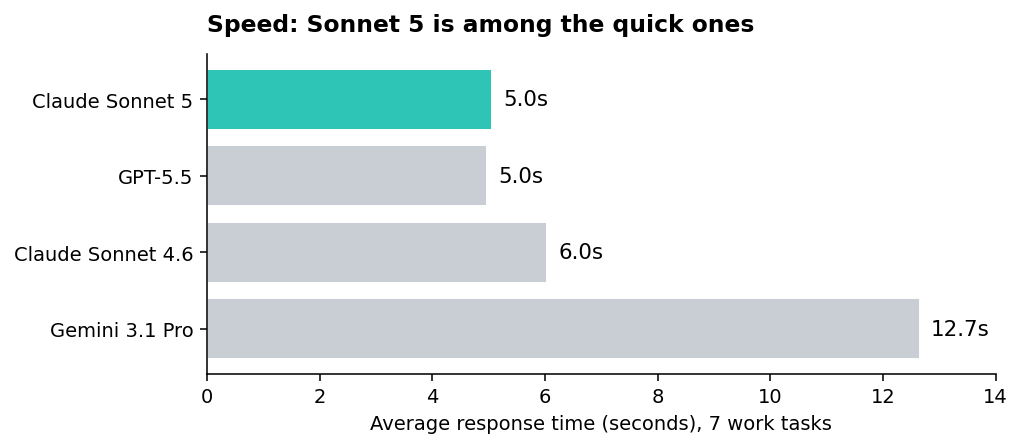 Average response time across the seven tasks.
Average response time across the seven tasks.
Sonnet 5 and GPT-5.5 are the fast ones, both averaging around 5 seconds a response. Sonnet 4.6 sits a little behind at 6 seconds. Gemini 3.1 Pro is two to three times slower than any of them, at nearly 13 seconds, which is the trade-off for being the most compact writer of the four.
On the four everyday tasks, the three current models are close to level; any of them would do the job. GPT-5.5 structured its procedure with explicit sub-steps under each heading, which reads as the most beginner-proof of the four. Gemini's was the most compact by a distance. Sonnet 5's was correctly ordered and clearly written, and, true to form, the longest.
On the three traps, the honesty checks and the table read, all three current-generation models passed every one. GPT-5.5 was the most direct in calling out the false "trending up" note: "we should treat this as a capacity and service-quality concern rather than a positive trend." Gemini was the only one to reliably catch the missing allowance figure. The generation gap only shows up against Sonnet 4.6, and only on the table.
Net effect: Sonnet 5's edge is judgement and reading, its cost is length. GPT-5.5 is the terse, fast all-rounder. Gemini is the thorough, patient one you'd want when speed doesn't matter.
What I'd actually do with it
Trust it more than you probably do on reading a table, a chart or a screenshot someone's sent you, the same territory covered in using AI for spreadsheets and data. That held across four separate runs, not one. Hand it the brief that's missing half its information rather than bluffing your way through it yourself: it will tell you what it actually needs instead of guessing on your behalf. Tell it explicitly to be brief, and still expect to cut it down, especially on anything procedural. And check any number, unit or currency symbol it introduces itself before it goes out the door. The one time in four it slipped in this whole test, that's precisely what it invented.
FAQ
What is Claude Sonnet 5 actually good at?
Reading figures accurately, and giving useful, specific refusals when it doesn't have enough information to answer safely. In a controlled test it caught a planted arithmetic error in a sales table image across four separate runs, and when asked to recommend a vendor from incomplete data, it listed exactly what information it would need rather than guessing.
Are there benchmarks for Claude Sonnet 5?
This is a hands-on test rather than a synthetic benchmark score: seven real work tasks, run identically across four models, with the actual outputs compared side by side rather than reduced to a single leaderboard number. What's measured is accuracy on planted errors, the quality of its refusals, response speed and output length, not a standardised academic benchmark suite.
What are Claude Sonnet 5's weaknesses?
It writes longer than necessary, even when explicitly told to be concise, averaging around a third more output than GPT-5.5 and roughly double Gemini 3.1 Pro's length on the same tasks. It can also occasionally invent a small unverified detail: in one of four test runs it labelled a data error with a currency figure that wasn't in the source at all.
Is Claude Sonnet 5 better than GPT-5.5 or Gemini 3.1 Pro?
On ordinary work tasks, the three are close to level. Sonnet 5 and GPT-5.5 are the fastest, at around 5 seconds a response. Gemini is two to three times slower but was the only one to reliably catch a specific missing figure in a policy document across repeated tests. Sonnet 5's edge is in refusals and reading figures; GPT-5.5's is speed and brevity.
Does this test compare Claude Sonnet 5 to Claude Opus?
No. This test compares Sonnet 5 to GPT-5.5, Gemini 3.1 Pro and its own predecessor, Claude Sonnet 4.6, on the same seven work tasks. Opus wasn't part of this particular run.
What changed between Claude Sonnet 4.6 and Sonnet 5?
The clearest jump is in reading data accurately. Given the same sales table image with a planted arithmetic error, Sonnet 4.6 missed the error across four separate runs. In its best attempt it noticed a total didn't add up but blamed the wrong figure. Sonnet 5 caught the actual error correctly in all four runs.
Can I trust Claude Sonnet 5 with real numbers and figures?
More than its predecessor, but not without checking. It reads tables and screenshots reliably and will tell you when it doesn't have enough information rather than guessing, but check any number, unit or currency it introduces itself before passing it on. That's the one place it slipped in this test.