// in this post
- What changes, and what doesn't, on 7 July
- The price of the premium
- What the premium actually buys
- Where the tokens go, and why they cost what they do
- Use the model for what it is
- What it would cost me to ignore that
- The fair criticism
- What I'm doing, and what I'd suggest
- FAQ
- Sources
Over the last quarter my AI agents worked through a little over 3 billion tokens, across 7,169 separate messages. They wrote and debugged code, drafted articles, ran research, handled client work, and kept my own software product and this website ticking over. Priced at standard pay-as-you-go API rates, that quarter of work would have cost about £2,900, or $3,685 in the dollars Anthropic actually bills in. I ran it on a flat plan that costs £112 a month.
From 7 July, Anthropic's newest and most capable model, Claude Fable 5, leaves my Max plan and moves onto separate, paid usage credits. Plenty of people are reading that as a nudge to upgrade. I costed it properly against my own usage first, and I am staying where I am. If you run anything like the workloads I do, I would look hard before switching too.
What changes, and what doesn't, on 7 July
Fable 5 came back online for everyone on 1 July, after the export-control block earlier in the summer was lifted. Until 7 July it is included in the Pro, Max and Team plans for up to half of your weekly usage limit. After that date it moves off the subscription and onto paid usage credits, billed per token.
Nothing else changes. Opus and Sonnet stay on my plan exactly as they were, and I will keep using them the way I always have. The only new decision Anthropic has handed me is whether to pay extra, on top of the plan, to make Fable my default. So I treated it as what it is, a purchasing decision, and did what I would tell any client to do. I looked at the numbers before the marketing.
The price of the premium
Fable 5 is Anthropic's most capable widely released model, built, in their own words, for the most demanding reasoning and long-horizon agentic work. It is also the most expensive in the range by a distance: $10 per million input tokens and $50 per million output, which is exactly double Opus 4.8 on both counts, and more than three times Sonnet 5.
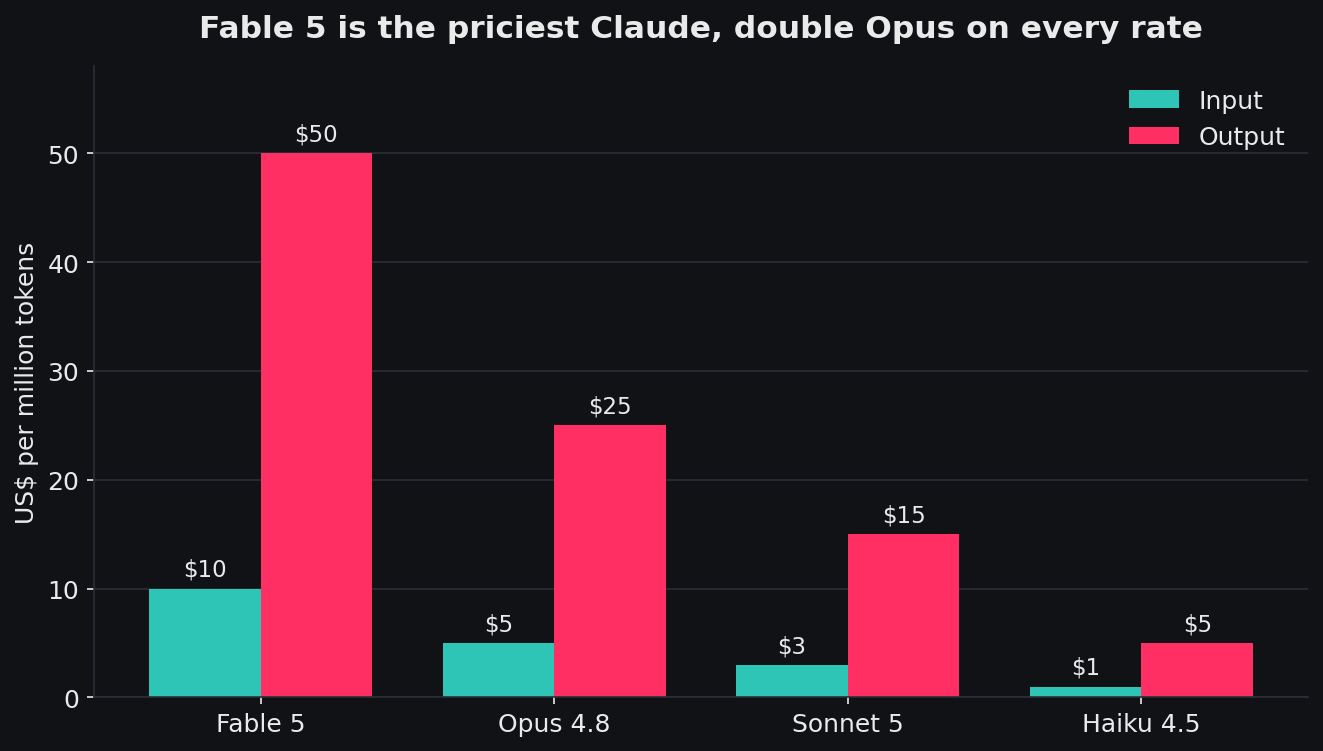 Anthropic bills in US dollars. Sonnet 5 is shown at standard pricing; its introductory rate is lower until 31 August.
Anthropic bills in US dollars. Sonnet 5 is shown at standard pricing; its introductory rate is lower until 31 August.
There is a second cost that is easy to miss. Fable's thinking is always on. You cannot switch it off, you can only turn its effort up or down, and the reasoning it does is billed as output at that $50 rate even though you never see it. So on top of a headline price that is already the steepest in the range, you are paying for a layer of hidden work you have no way to inspect.
What the premium actually buys
A high price is only a problem if you are getting nothing for it, so I tested that directly. I gave the same two jobs to Fable 5, Opus 4.8, Sonnet 5 and Haiku 4.5. The first was ordinary: draft an 1,100-word how-to article. The second was harder: build a twelve-month membership pricing model, with a correct answer I had worked out by hand first so I could mark them.
On the drafting job, all four produced something publishable, and the quality was flat across Fable, Opus and Sonnet. Fable barely engaged its reasoning on that task, so its extra cost was close to pure sticker premium. You paid more and got the same paragraph.
On the hard reasoning job, every current model reached the correct answer except Haiku, which built the right tables and then misread its own figures. The one that stood out was Opus, running with its thinking turned off, at eight cents. It matched what Fable produced at high effort for forty-two cents. Same answer, a fifth of the price. Sonnet landed the same answer too, but wrote more to get there, which is why it cost more than Opus on that particular job, a useful reminder that the per-token price is only ever half the story.
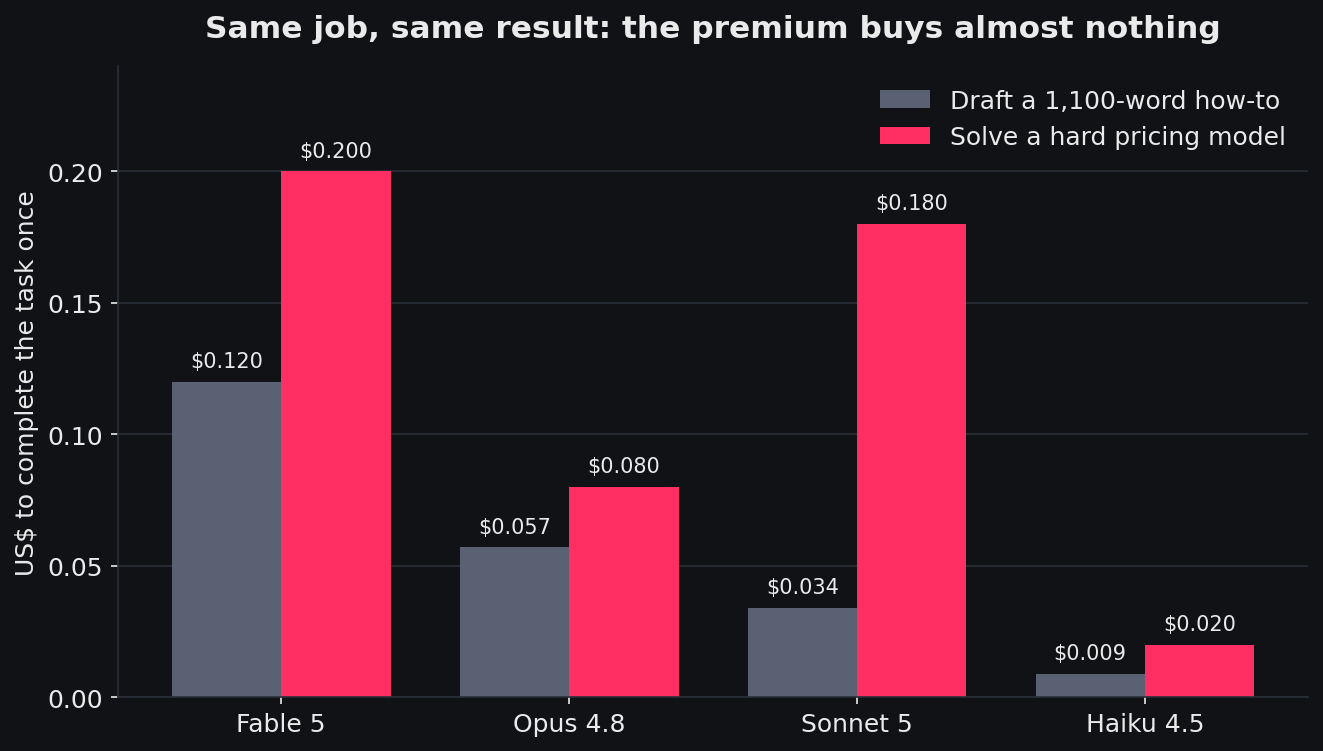 Cost to complete each task once. Fable is shown at low effort; turning its effort to high on the reasoning task doubled its cost to $0.42 for an identical answer.
Cost to complete each task once. Fable is shown at low effort; turning its effort to high on the reasoning task doubled its cost to $0.42 for an identical answer.
That is two tasks, not a full battery, and I want to be fair about what it does and does not show. The hard task was still within reach of the cheaper models, so this is not proof that Fable is never worth it. Its real advantage is on the demanding, long-horizon agentic work I did not test here. What the test does show is narrower and, for most people, more useful: on the everyday work that fills an actual week, the premium buys nothing you can point to.
Where the tokens go, and why they cost what they do
That per-token point matters more than it looks, because on real agent work the bill is not mostly about the words the model writes back. First, where the work goes. The bulk of it, more than 40%, was building my own software product, with the rest spread across content, this website, research, a client engagement and a scatter of side projects. It is the unglamorous middle of real work, nothing you would put in a demo.
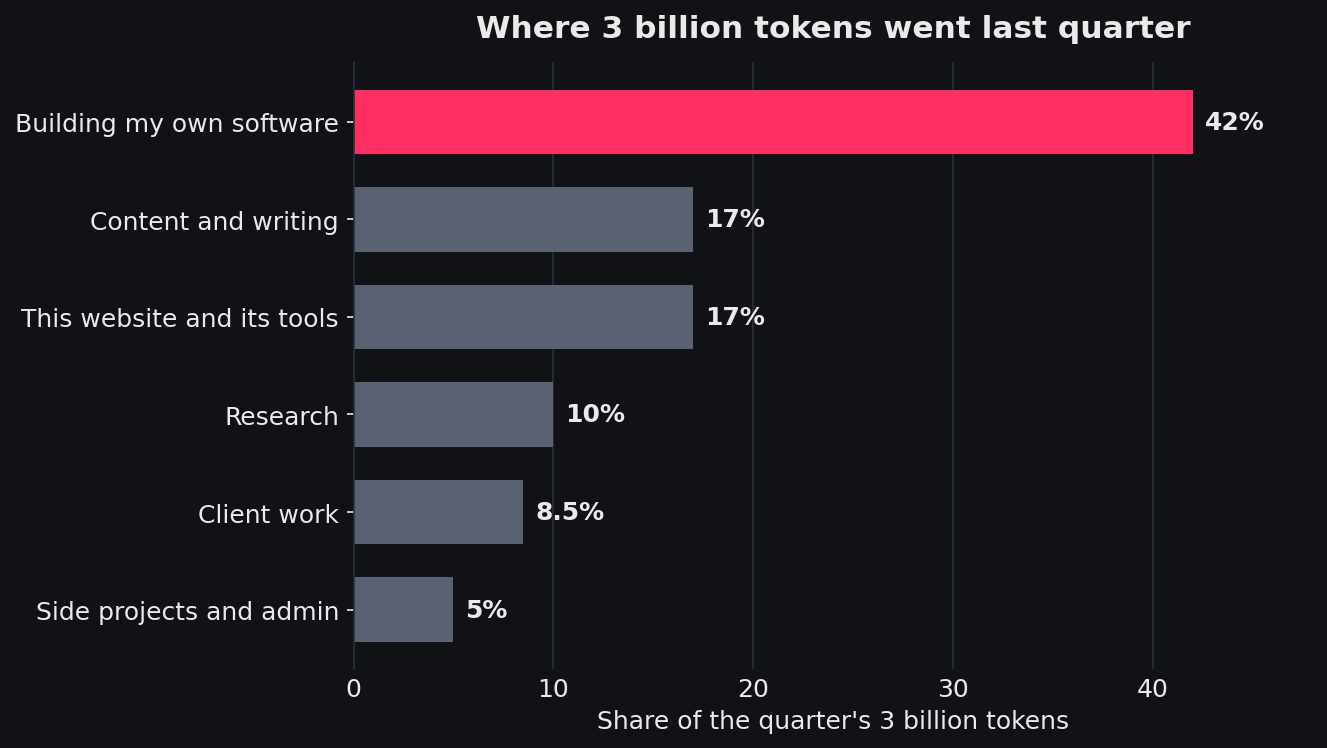 Where the quarter's 3 billion tokens went, by area of work.
Where the quarter's 3 billion tokens went, by area of work.
And the reason it costs what it does is not the output. When I audited the quarter, 94% of my input tokens were cache reads, and about half my total cost was the cache writes that keep a large context, a whole codebase, a long prompt, warm enough to work with. The expense is holding the material in memory while the agent works through it, not the thinking the model does or the answer it hands back.
Which means the model you pick is only one of three levers, and on its own it is the crude one. Token cost, model capability, and how you actually use the thing all pull on the final bill together. A cheaper model used carelessly, holding more context than it needs and re-reading the same files, can quietly cost more than a dearer one used well.
Use the model for what it is
This is the part I would underline for anyone weighing an upgrade. Anthropic did not build Fable to be your default. They built it for the hardest, longest-running work, and they say so plainly. Treating it as the everyday tool, the thing every agent reaches for by reflex, is how you end up paying twice over for most of the work that never needed it.
The discipline is old and dull and it works: match the model to the job. Draft on Sonnet. Let Haiku take the small mechanical jobs. Keep Opus for the work that needs real reasoning. Reserve the frontier model for the rare problem that has earned it, and pay for that one problem, not for a standing subscription to overkill. It is the same habit good delegation has always needed, knowing which task deserves which person, applied to a fleet of models instead of a team of people.
What it would cost me to ignore that
To put a figure on it, I repriced my entire quarter as if every token had run on a single model. The shape is stark.
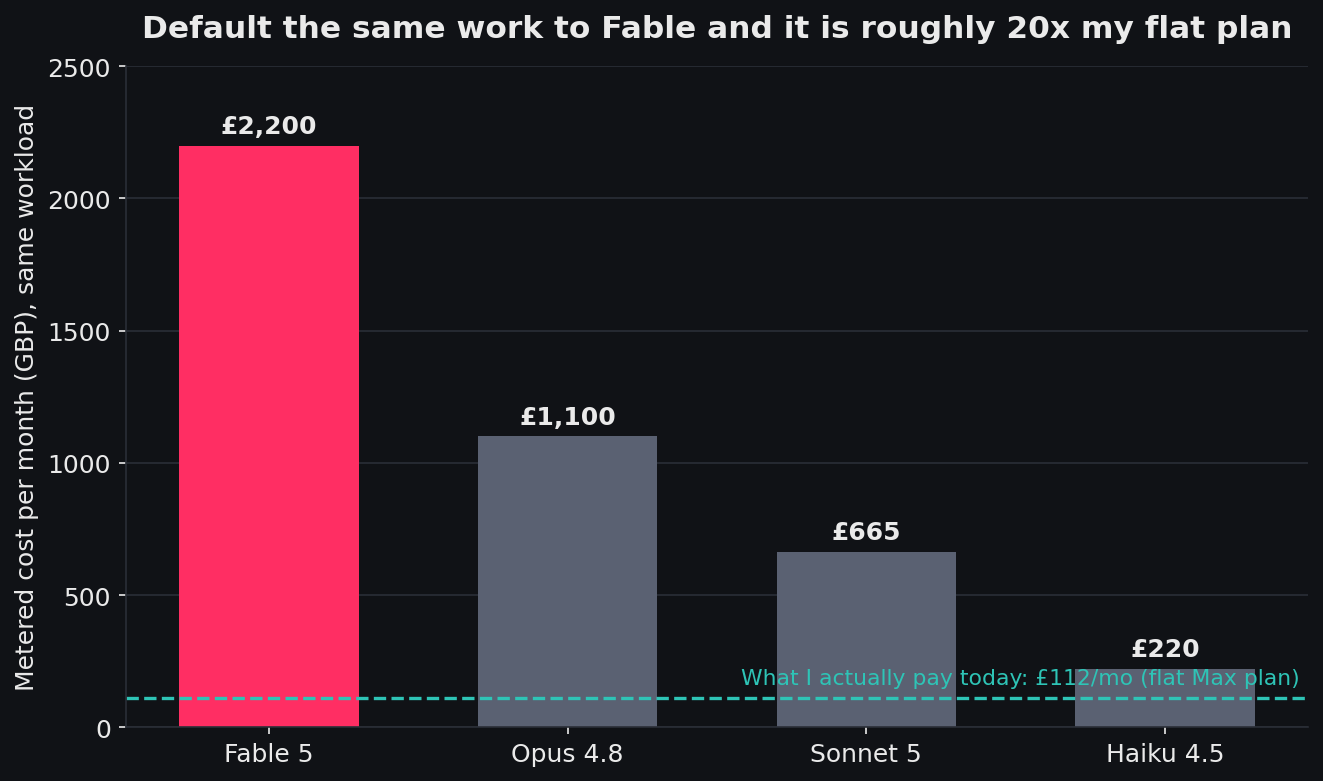 The same quarter of agent work, repriced per month at metered API rates. The dashed line is what I actually pay on the flat Max plan.
The same quarter of agent work, repriced per month at metered API rates. The dashed line is what I actually pay on the flat Max plan.
On my current mix, weighted heavily toward Opus, the work runs on a flat £112 Max plan. Default the same workload to Fable and, because Fable now sits outside the plan, you leave flat-rate pricing behind and pay metered credits: roughly £2,200 a month on average, and closer to £4,400 in a heavy build month. That is around twenty times what the same work costs me now, for output my own tests could not tell apart on the jobs I do most days.
I should be straight about the limits of that figure. It holds my token counts fixed, and Fable, with its always-on thinking, would generate more of them than Opus did, so the real number would be higher, not lower. My usage is also spiky, a quiet month is a fraction of a build month, so the honest picture is a band rather than a flat rate. And the £2,900 from the top of this piece is the dollar-equivalent at API rates, not a bill I paid. I ran the quarter on the £112 plan because I stayed on it and used the whole range.
The fair criticism
None of this makes Anthropic villains, and I want to be careful here, because I like their models and use them all day. Bringing Fable back after the export-control block was the right call, and it is more capable at the top end. But it is fair to say the terms have got less friendly than the ones that drew a lot of us in.
You are asked to pay double the next model down. You are billed for reasoning you cannot see and cannot switch off. The most capable model is handed to subscribers for a single week and then moved behind metered credits. And it carries thirty-day data retention with no zero-retention option, so the privacy-conscious cannot opt out. Each of those is defensible on its own. Together they mark a real shift: a generous flat plan that once made heavy experimentation cheap is giving way to a metered top tier that quietly rewards reaching for the most expensive option. If that irritates people who have used these tools for a while, it should. It is a fair thing to be irritated by.
What I'm doing, and what I'd suggest
So I am not switching. I will keep Opus and Sonnet on the flat plan for the daily work, and on the rare occasion a problem is genuinely hard and long-running, I will buy Fable credits for that single job and no more. That is the whole of my plan.
If you are facing the same decision, do not take my numbers, take my method, because your usage is not mine. Pull your own; most tools will show you where your tokens go. Run your real recurring task through two or three tiers and see whether the dearer one changes the output in a way you can point to. Then default to the cheapest model that clears the bar your work sets, and keep the expensive one for the jobs that earn it. You will most likely find, as I did, that the model you are being nudged to upgrade to is waiting to be used far more often than your work requires.
FAQ
How much does Claude Fable 5 cost?
Fable 5 is priced at $10 per million input tokens and $50 per million output tokens, which is double Claude Opus 4.8 on both and more than three times Sonnet 5. From 7 July 2026 it is billed via paid usage credits rather than being included in the Pro, Max and Team subscriptions.
Is Claude Fable 5 worth it?
For the genuinely hard, long-horizon reasoning work it is built for, it can be. For everyday drafting and mid-weight analysis, a hands-on test found no quality gain over the cheaper Opus or Sonnet, at up to twenty times the cost. The sensible approach is to reserve it for the rare task that has actually earned it.
What changed with Fable 5 on 7 July 2026?
Fable 5 came back online for everyone on 1 July and was included in the Pro, Max and Team plans for up to half of weekly usage limits until 7 July. After that date it moves off the subscription onto separate paid usage credits. Opus and Sonnet are unaffected and stay on the plans as before.
Can you turn off Fable 5's thinking?
No. Fable's adaptive thinking is always on and cannot be disabled; you can only raise or lower its effort level. That reasoning is billed as output tokens even though the raw thinking is never shown to you.
Which Claude model should I use for everyday work?
Match the model to the task. Haiku handles small mechanical jobs, Sonnet is strong for drafting, Opus is the workhorse for genuine reasoning, and Fable is best kept for rare, demanding, long-running work. Defaulting every task to the most capable model is the expensive mistake.
Sources
- Introducing Claude Fable 5 and Claude Mythos 5, Anthropic. Pricing, the always-on adaptive thinking and effort dial, and the 30-day data-retention requirement.
- Redeploying Fable 5, Anthropic. The 1 July global availability and the move from subscription inclusion to paid usage credits on 7 July.
- Usage, repricing and per-task cost figures are drawn from the author's own Claude Code agent logs over 77 days (16 April to 2 July 2026), a detailed sample rather than a guaranteed-complete history. Pound figures are approximate; Anthropic bills in US dollars.